
This post is being reworked for Windows 2019
Introduction
OK, so you want to install a cluster? This is not a “Should I build a cluster?” post, this is a “How to build a proper cluster” post. I like checklists, so I made a Windows Failover Cluster installation checklist. Some of the points have their own post, some are just a short sentence. I will add more details as time allows. The goal is to share my knowledge about how to build stable clusters. I may disagree with other best practices out there, but this list is based on my experience, what works in production and what does not. I use it to build new clusters, as well as troubleshooting clusters made by others. Clustering is so easy that anyone can build a working cluster these days, but building a stable production worthy cluster may still be like finding you way out of a maze. A difficult maze filled with ghosts, trolls and angry badgers.
There are some things you need to know about this post before you continue reading:
- This list is made for production clusters. There is nothing stopping you from building a lab using this list, but if you do as I say, you will build a very expensive lab.
- I work with SQL Server, Hyper-V and File clusters. This list may work for other kinds of clusters as well, but I have not tested it on recent versions.
- This list was originally published in 2014 for Windows 2008R2 up until Windows 2012R2. It os now updated for Windows Server 2019. I will try to add version specific instructions when necessary.
- This list is for physical clusters. I dislike virtual clusters, because most organizations are not clever enough to create functioning virtual production clusters that won’t fail miserably due to user error someday. (By “virtual clusters” I mean cluster nodes on top of hypervisors, not clustered hypervisors). It is however entirely possible to build virtual clusters using this list, especially if you employ technology such as Virtual FC.
- This is my checklist. I have spent more than a decade honing it, and it works very well for me. That does not guarantee that it will work for you. I welcome any comments on alternative approaches, but don’t expect me to agree with you.
- This list is mostly written in a “How to do it” manner, and may be lacking in the “But why should I do it” department. This is due to several reasons, but mostly a lack of time on my part. I do however want you to know that there are several hours, if not days of work behind each point.
- Updates will be made as I discover new information.
- The list is chronological. That is, start at the top and make your way down the list. If you jump back and forth, you will not achieve the desired result.
- This list is based on the GUI version of Windows Server, not Core. You can build clusters on core, but I do not recommend it. Clusters may be very finicky to troubleshoot when things go wrong, and doing so on Windows Core is like trying to paint a room through the keyhole.
- Understanding this list requires knowledge of Active Directory and basic knowledge of Failover Clustering.
- There are many special cases not covered. This list is for the basic 2-10 node single datacenter cluster. The basic rules still apply though, even if you have nodes in four datacenters and use a hybrid cloud setup.
The design phase
In the design phase, there are a lot of decisions you have to make BEFORE you start building the cluster. These are just a few of them:
- How many nodes do you need? Remember you need at least one node for HA (High Availability). Depending on the total number of nodes you may need several standby nodes. Some managers will complain about the extra nodes just sitting there unused, but they forget that they are there to provide HA. No matter the number of nodes, make sure the hardware is as equal as possible. I don’t care what the manual says, having cluster nodes with different hardware in them is a recipe for disaster. If possible, all nodes should be built on the same day by the same persons and have consecutive serial numbers.
- How many network fabrics do you need? And how many can you afford? See Networks, teaming and heartbeats for clusters for more information. This is where most troublesome clusters fail.
- Will you use shared storage? And what kind of shared storage? In short: FCOE is bad for you, ISCSI is relatively cheap, SMB3 is complicated and may be cheap, shared DAS/SAS is very cheap, FC is the enterprise norm and infiniband is for those who want very high performance at any cost. In most cases you will have to use what is already in place in your datacenter though. And it is usually better to have something your storage guys are used to supporting. Just remember that storage is very important for your overall performance, no matter what kind of cluster. For file clusters, high throughput is important. For SQL Server, low latency is key and you should use FC or infiniband.
- What kind of hardware should you use in your cluster nodes? Currently, these are my opinions, based on my personal experience. As mentioned above, these are my opinions, you may come to other conclusions. My opinions on this change frequently as new generations are released, but here goes:
- Emulex should stop making any kind of hardware. It is all bad for you and bad for your cluster. If you are having trouble with cluster stability and you have Emulex made parts in your nodes, remove them at once.
- QLogic make good FC HBAs. If you have a FC SAN, QLogic HBAs are highly recommended. If you have QLogic network adapters on the other hand, use them for target practice.
- Broadcom network adapters used to be good, but the drivers for Windows are getting worse by the minute.
- Intel X520 is my current favorite network adapter.
- Use Brocade FC switches only. They are sold under many other brand names as well, I have seen them with both HP and IBM stickers.
- Use Cisco or HP network switches, but do not use them for FC traffic.
- Make sure your nodes have local disk controllers with battery or flash backed cache. Entry level disk controllers are not worth the cardboard box they are delivered in.
- Intel Xeon CPUs currently reigns supreme for most applications. There are however some edge cases for SQL Server where AMD CPUs will perform better. I recommend reading Glenn Berry’s blogs for up to date SQL Server CPU information.
- HP, IBM and Dell all make reasonably good servers for clustering. Or, I should say equally bad, but better than the alternatives.
- RACK or Blade?
- RACK servers
- are easier to troubleshoot
- are versatile
- give you a lot of expansion options
- are cheaper to buy
- Blade servers are
- space efficient
- cheaper to maintain if you rent rack space
- easier to install
- limited in terms of expansion options
- RACK servers
- Where should your nodes be located physically? I do not recommend putting them all in the same rack. The best solution is to put them in separate rooms within sub-millisecond network distance. You can also place them in separate data centers with a long distance between them if you do not use shared storage or use some kind of hybrid solution. I do not recommend SAN synchronization to data centers far, far away though, it is better to have synchronization higher up in the stack. If you only have one datacenter, place the nodes in different racks and make sure they have redundant power supplies.
- Talking about power, your redundant power supplies should be connected to separate power circuits, preferably with each connected to an independent UPS.
- What domain should your servers be member of, and which organizational unit should you use? Failover clustering will not work without Active Directory. The Active Directory role should NOT be installed on the cluster nodes. You should have at least two domain controllers, one of which should be a dedicated physical machine. I know that MS now supports virtualizing all your domain controllers, but that does not mean that you should do it, or that it is smart to do so. I would also recommend creating a separate OU for each cluster.
- What account should you use to run the installation? I would recommend using a special cluster setup account, as some cluster roles latch on to the account used during installation and become unstable if that account is deleted at a later date. The account should be a domain administrator, and should be set to automatically deactivate at some point in the near future after you are done with the cluster setup. You can then re-activate it for the next cluster installation by changing the expiration date and password.
- And then there are a lot of product and project specifics, such as storage requirements, CPU and memory sizing and so on, all of which may affect your cluster design.
The actual checklist
All list items should be performed on each node in the cluster unless specified otherwise. You can do one node at the time or all at once until you get to cluster validation. All nodes should be ready when you run cluster validation. I find it easiest to remember everything by doing one list item for each node before I move on to the next, making notes along the way.
- Install Windows Server
- Copy any required media, drivers etc. to a folder on each node
- Activate a machine proxy if you use a proxy server to access the internet. See Proxy for cluster nodes for more information.
- Check whether the server is a member of the domain, and add it to the domain if necessary
- Make sure all your drivers are installed using Device Manager
- Make sure you are running current BIOS, Remote Access, RAID, HBA and Network firmware according with your patch regime. If in doubt, use the latest available version from your server vendor. Do NOT download drivers and firmware from the chip vendor unless you are troubleshooting a specific problem.
- Make sure your drivers are compatible with the firmware mentioned above.
- Add the failover cluster features:
Install-WindowsFeature -Name Failover-Clustering –IncludeManagementTools
- If this is a Hyper-V host, install the Hyper-V role
Install-WindowsFeature –Name Hyper-V -IncludeManagementTools -Restart
- Verify your network setup. Networks, teaming and heartbeats for clusters
- Check network adapter names and binding order. The public interface (the one facing the domain controllers) should be at the top of the binding order, and adapters should have the same name on each cluster node.
- Disable IPv6. See How to disable IPv6
- Remove duplicate persistent routes. Details
- Disable NICs that are not in use
- Install any prerequisites required by your shared storage. Check with your SAN admin for details.
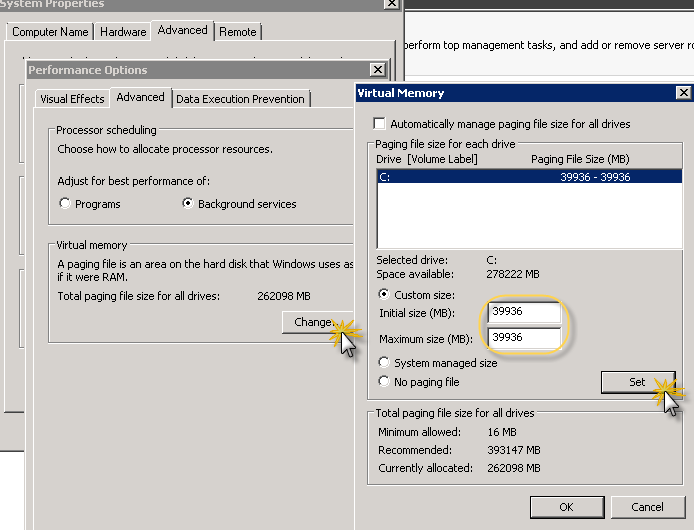
- Change page file settings according to Page file defaults
- Activate Microsoft Update http://update.microsoft.com/microsoftupdate
- Run Windows update
- Install cluster hotfixes. See Does your cluster have the recommended hotfixes?
- Select the High Performance power plan, both in Windows and in the BIOS/UEFI
- Verify automount settings for Failover Clustering
- If you are using shared storage, verify storage connections and MPIO in accordance with guidelines from your SAN vendor. Most SAN vendors have specific guidelines/whitepapers for Failover Clustering.
- If you are creating a Hyper-V cluster, this is the time to create a virtual switch
- Validate the configuration: Validating a Failover Cluster. Do not continue until your cluster passes validation. I have yet to see a production cluster without validation warnings, but you should document why you have each warning before you continue.
- Create the cluster: Creating a Failover Cluster
- Verify the Quorum configuration. If you are using Windows 2012, make sure dynamic quorum is enabled. If you use shared storage, you should always have a quorum witness drive (even if you don’t use it). The create cluster wizard will without fail select another quorum witness drive than the one you intended to use, so make sure to correct this as well.
- Grant create computer object permissions to the cluster. This is necessary for installation of most clustered roles, and this is why each cluster should have its own OU.

























{kind=link}